
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- PYTHON
- jpa
- nosql
- java
- 플로이드-워셜 알고리즘
- 자료구조
- redis
- Docker
- javascript
- 완전탐색
- HTML
- websocket
- CSS
- 알고리즘
- 백준
- DFS
- 프로그래머스
- 데이터베이스
- mysql
- CS
- 영속성 컨텍스트
- 운영체제
- Algorithm
- BFS
- 트랜잭션
- spring
- Data structure
- db
- OS
- It
- Today
- Total
If at first you don't succeed, try again
[자료구조] Hash Table(해시 테이블)(Python) 본문
* 개요
Hash Table(해시 테이블)은 Index(색인)에 해시값을 사용하는 자료구조로, 정렬을 하지 않고도 빠른 검색, 빠른 삽입이 가능하다는 특징을 가진다. 해시는 리스트를 사용하는 접근법은 동일하지만, 여기에 색인 개념이 추가되어 있다. 충분히 큰 공간을 할당받은 다음, 해시 함수를 이용하여 고유 인덱스를 생성한다. 그리고 이 고유 인덱스와 맞는 위치에 데이터를 저장한다. 예를 들어, 0 ~ 100까지의 데이터를 담을 수 있는 리스트를 생성하고, '사과' 라는 단어에 해시 함수를 적용하여 50이라는 인덱스가 생성되면, 리스트의 50번 인덱스에 '사과'를 저장하는 방식이다. 언제나 동일한 해시 값을 반환하기 때문에 '사과'를 입력하면 50이라는 인덱스가 나오므로, 정렬하지 않고도 데이터를 탐색할 수 있게 된다. 하지만 동일한 해시 값이 2개 이상 존재하는 경우 충돌이 일어나게 되는데, 이를 Hash Collision(해시 충돌)이라 한다. 해시 충돌을 방지하기 위한 방법은 대표적으로 2가지가 있다. 그것은 Open Hashing(오픈 해싱)과 Close Hashing(클로즈 해싱)이다.
* Open Hashing(오픈 해싱)
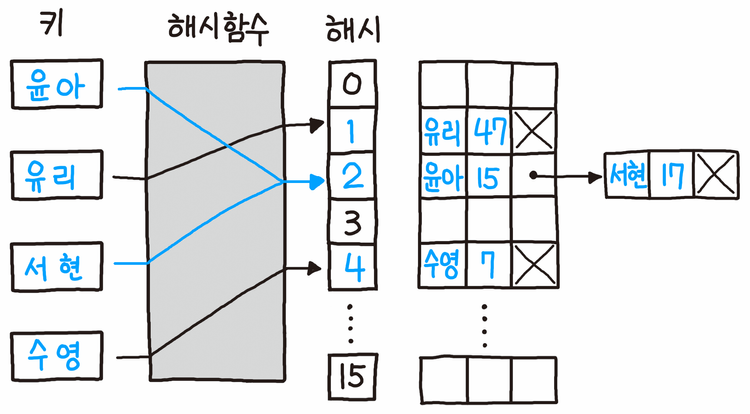
Open Hashing(오픈 해싱)은 해시 테이블의 충돌 문제를 해결하는 방법 중 하나이다. 오픈 해싱은 개별 체이닝 기법(Separate Chaining)을 사용한다. 개별 체이닝은 충돌 발생 시 그림과 같이 연결 리스트로 연결하는 방식이다. 해시 값 충돌이 일어난 윤아와 서현은 윤아의 다음 아이템이 서현인 형태로 서로 연결 리스트로 연결되었다. 이처럼 기본적인 자료구조와 임의로 정한 간단한 알고리즘만 있으면 되므로, 개별 체이닝 방식은 인기가 높다. 원래 해시 테이블 구조의 원형이기도 하며, 가장 전통적인 방식으로 흔히 해시 테이블이라고 하면 바로 이 방식을 말한다. 파이썬에서는 연결 리스트를 쓰지 않고 이중 리스트로 간단하게 구현할 수 있다.
* 파이썬으로 구현한 Open Hashing
연결 리스트를 사용하지 않고 이중 리스트로 오픈 해싱을 구현하였다.
# 해시테이블 - 오픈 해싱
class OpenHash :
def __init__(self, table_size) :
self.size = table_size
self.hash_table = [0 for i in range(self.size)]
def getKey(self, data) :
self.key = ord(data[0])
return self.key
def hashFunction(self, key) :
return key % self.size
def getAddress(self, key) :
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value) :
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0 :
for i in range(len(self.hash_table[hash_address])) :
if self.hash_table[hash_address][i][0] == key :
self.hash_table[hash_address][i][1] = value
return
self.hash_table[hash_address].append([key, value])
else :
self.hash_table[hash_address] = [[key, value]]
def read(self, key) :
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0 :
for i in range(len(self.hash_table[hash_address])) :
if self.hash_table[hash_address][i][0] == key :
return self.hash_table[hash_address][i][1]
return False
else :
return False
def delete(self, key) :
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0 :
for i in range(len(self.hash_table[hash_address])) :
if self.hash_table[hash_address][i][0] == key :
# 만약 해시 테이블의 해시 인덱스에 있는
# key-value가 하나라면 0으로 초기화
if len(self.hash_table[hash_address]) == 1 :
self.hash_table[hash_address] = 0
else :
del self.hash_table[hash_address][i]
return
return False
else :
return False
oh = OpenHash(5)
oh.save('aa', '1234')
print(oh.read('aa'))
data1 = 'aa'
data2 = 'ad'
print(ord(data1[0])) # 97
print(ord(data2[0])) # 97
# data1[0]과 data2[0]는 동일한 해시 값을 지닌다.(97 % 5)
oh.save(data2, '1111')
print(oh.hash_table)
# 동일한 key값을 지니므로 해당 인덱스에 append된 채로 출력 - 개별 체이닝
print(oh.read('aa')) # aa
print(oh.read('ad')) # ad
oh.delete('aa') # key 'aa'를 활용하여 해당 key-value 삭제
print(oh.hash_table)
print(oh.delete('dd')) # key 'dd'는 존재하지 않으므로 False 반환
oh.delete('ad')
# key 'ad'를 활용하여 해당 key-value 삭제
# 하지만 해당 인덱스의 값의 길이가 1이므로 0으로 초기화
print(oh.hash_table)* Close Hashing(클로즈 해싱)

Close Hashing(클로즈 해싱)은 Linear Probing(선형 탐사), Open Addressing(오픈 어드레싱)으로 불리우기도 하며, 충돌 발생 시 그림과 같이 탐사를 통해 빈 공간을 찾아나서는 방식이다. 사실상 무한정 저장할 수 있는 오픈 해싱과는 달리, 클로즈 해싱은 전체 슬롯의 개수 이상은 저장할 수 없다. 충돌이 발생하면 테이블 공간 내에서 탐사(Probing)를 통해 빈 공간을 찾아 해결하며, 이 때문에 오픈 해싱과는 달리, 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장은 없다. 또한 클로즈 해싱은 충돌이 발생할 경우, 해당 위치부터 순차적으로 탐사를 하나씩 진행한다. 특정 위치가 선점되어 있으면, 바로 그 다음 위치를 확인하는 식이다. 이렇게 탐사를 진행하다가 비어 있는 공간을 발견하면, 삽입하게 된다. 특정 위치가 선점되어 있으면 바로 그 다음 위치를 확인하는 식이다. 이렇게 탐사를 진행하다가 비어있는 공간을 발견하게 되면 삽입하게 된다. 가장 가까운 다음 빈 위치를 탐사해 새 key를 삽입한다. 그림에서도 윤아 다음에 서현의 해시 값이 동일한 2로 충돌이 발생했고, 다음 번 빈 위치를 탐색하며 그 다음 위치이면서 빈 공간인 3에 서현이 들어가게 된다. 이처럼 선형 탐사 방식은 구현 방법이 간단하면서도, 의외로 전체적인 성능이 좋은 편이기도 하다. 성능이 좋은 이유는 오픈 해싱에 비해 저장 효율이 좋기 때문이다(전체 슬롯의 개수 이상 저장 불가).
* 파이썬으로 구현한 Close Hashing
이중 리스트로 클로즈 해싱을 구현하였다. 오픈 해싱과 코드는 비슷하지만, 다른 점은 특정 인덱스에 삽입을 하고자 할 때, 이미 그 위치가 선점되어 있다면, 바로 그 다음 위치를 확인하고 삽입하는 것이다.
class CloseHash :
def __init__(self, table_size) :
self.size = table_size
self.hash_table = [0 for i in range(self.size)]
def getKey(self, data) :
self.key = ord(data[0])
return self.key
def hashFunction(self, key) :
return key % self.size
def getAddress(self, key) :
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value) :
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0 :
for i in range(hash_address, len(self.hash_table)) :
if self.hash_table[i] == 0 :
self.hash_table[i] = [key, value]
return
elif self.hash_table[i][0] == key :
self.hash_table[i] = [key, value]
return
return None
else :
self.hash_table[hash_address] = [key, value]
def read(self, key) :
hash_address = self.getAddress(key)
for i in range(hash_address, len(self.hash_table)) :
if self.hash_table[i][0] == key :
return self.hash_table[i][1]
return None
def delete(self, key) :
hash_address = self.getAddress(key)
for i in range(hash_address, len(self.hash_table)) :
if self.hash_table[i] == 0 :
continue
elif self.hash_table[i][0] == key :
self.hash_table[i] = 0
return
return False
# 실행 예제
ch = CloseHash(5)
data1 = 'aa'
data2 = 'ad'
print(ord(data1[0])) # 97
print(ord(data2[0])) # 97
# data1[0]과 data2[0]의 해시 값은 같다.(97 % 5)
ch.save(data1, '1234')
ch.save(data2, '1111')
print(ch.hash_table) # [0, 0, ['aa', '1234'], ['ad', '1111'], 0]
print(ch.read(data1)) # 1234
ch.delete(data1) # key 'aa'를 활용하여 key-value 삭제
print(ch.hash_table)
ch.delete(data2) # key 'ad'를 활용하여 key-value 삭제
print(ch.hash_table)
* 해시 충돌로 인한 성능 저하

위의 두 가지 방법을 사용하였다고 하더라도 결과적으로 충돌로 인한 성능 저하는 막을 수 없다. 그림과 같이 수용률이 일정 이상 넘어서게 되면 저장 / 조회 성능이 모두 점점 떨어지며, 수용률이 일정량을 넘어가게 되는 경우에는 아예 리스트 자체의 크기를 키운 뒤에 재배열을 하는 방법을 사용한다. 다만, 이 과정 자체가 상당히 비용이 많이 드는 과정이라서 실시간으로 빠르게 처리해야 하는 환경에서는 무리가 있을 수 있다. 이럴 때는 큰 리스트를 하나 더 만들어서 적당한 타이밍에 몇개씩 점진적으로 옮기다가 다 옮기면 기존의 테이블을 없애 확장하는 방법도 있다. 다만 이 경우에는 메모리를 훨씬 더 많이 사용하게 된다. 또한 해시의 비트 수를 늘이는 방법도 있다. 항목 수가 적을 때에는 짧은(적은 비트 수) 해시와 작은 저장 공간을 사용하다가 충돌이 잦아지면 비트 수를 1비트 늘이고 저장공간도 2배로 늘인다. 그리고 항목을 점진적으로 확장된 공간으로 이전하게 함으로써 충돌을 줄일 수 있다. 이를 Consistent Hashing이라고 하며 분산 데이터베이스에서 데이터의 일관성을 유지하기 위해 사용하고 있다. 자료를 기본적으로 정렬하지 않은 상태로 저장하기 때문에 정렬된 순서로 접근하는 것은 비용이 매우 많이 들며 순회를 하는 경우에도 무효한 값들이 많아 실제 데이터의 개수만 순회하는 것보다 더 많은 비용이 들게 된다. 그리고 부하의 임계점을 적으면 50%, 많으면 75% 정도로 잡기 때문에 실제 데이터의 양보다 메모리를 많이 쓰게 된다.
'Computer Science > 자료구조(Python)' 카테고리의 다른 글
| [자료구조] Tree(트리)(Python) (0) | 2022.11.14 |
|---|---|
| [자료구조] Deque(덱)(Python) (0) | 2022.11.07 |
| [자료구조] Circular Queue(원형 큐)(Python) (0) | 2022.11.07 |
| [자료구조] Priority Queue(우선순위 큐)(Python) (0) | 2022.11.06 |
| [자료구조] Queue(큐)(Python) (0) | 2022.11.04 |



